

Cache avalanche:
Data is not loaded into the cache, or the cache fails in a large area at the same time, resulting in all requests to look up the database, resulting in database CPU and memory overload, or even downtime.
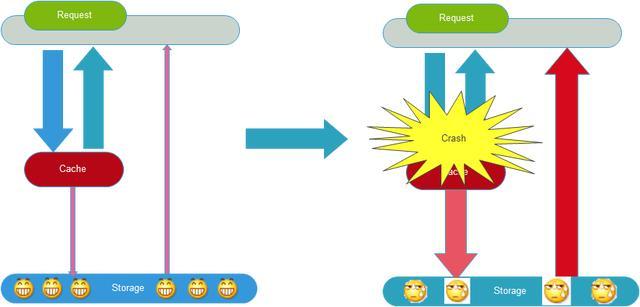
For example, a simple process of an avalanche:
- Large Area Fault of Redis Cluster
- Cache failure, but still a large number of requests to access the cache service R
edis . - After a large number of Redis failures, a large number of requests turn to MySQL database
- Mysql’s usage has increased dramatically, and it will not be able to carry it quickly or even go down directly.
- Because a large number of application services rely on MySQL and Redis services, it will soon become an avalanche of server clusters, and finally, the website will collapse completely.
How to prevent cache avalanche:
- High availability of caches
The cache layer is designed to be highly available to prevent large cache failures. Even if individual nodes, machines, or even computer rooms are down, services can still be provided, such as Redis Sentinel and Redis Cluster, which are highly available. - Cache degradation
Local caches such as ehcache can be used (temporarily supported), but current limitation, resource isolation (fusing), degradation and so on are the main ways to access source services.
When the number of visits increases dramatically and service problems arise, it is still necessary to ensure that the service is still available. The system can automatically degrade according to some key data, or can configure switches to achieve manual degrade, which involves the cooperation of operation and maintenance.
The ultimate goal of downgrading is to ensure that core services are available, even if they are harmful.
For example, in recommendation services, many are personalized needs, if personalized needs can not provide services, you can downgrade to supplement hot data, so as not to create a big gap in front-end pages.
Before downgrading, the system should be sorted out, such as: which business is the core (must be guaranteed), which business can allow temporary non-provision of services (using static page replacement), and with the core indicators of the server, after setting the overall plan, such as:
(1) General: For example, some services can be degraded automatically if they are out of time occasionally due to network jitter or when the service is on line;
(2) Warning: Some services have fluctuations in success rate over a period of time (e.g. between 95% and 100%) and can be automatically or manually downgraded and alerted;
(3) Errors: for example, the availability rate is less than 90%, or the database connection pool is exploded, or the number of visits suddenly increases to the maximum threshold that the system can withstand. At this time, it can automatically or manually degrade according to the situation;
(4) Serious errors: For example, data errors due to special reasons require urgent manual demotion. - Redis backup and fast preheating
1) Redis data backup and recovery
2) Fast cache preheating - Exercise in advance
Finally, it is suggested that before the project is launched, after the drill cache layer is down, the load situation of the application and the back end as well as the possible problems should be previewed in advance for high availability, and the problems should be found in advance.
Cache penetration
Cache penetration refers to querying a nonexistent data. For example, if Redis is not hit from the cache, you need to query from MySQL database, and if you can’t find the data, you don’t write it to the cache. This will cause the non-existent data to be queried to the database every time, resulting in cache penetration.
Solutions:
If the query database is empty, set a default value to store in the cache directly, so that the second time to get the value in the buffer, and will not continue to access the database. Set an expiration time or replace the value in the cache when it has value.
You can set some formatting rules for keys, and then filter out irregular keys before querying.
Cache concurrent
Concurrency here refers to the concurrency problem caused by multiple Redis clients setting keys at the same time. In fact, Redis itself is a single-threaded operation, multiple clients operate concurrently, according to the principle of first-come-first-execute, first-come-first-execute, the rest of the blocking. Another solution, of course, is to serialize Redis. set operations in a queue, one by one.
Cache preheating
Cache preheating is to load the relevant cached data directly into the cached system after the system is online.
This can avoid the problem of querying the database first and then caching the data when the user requests it! Users directly query the pre-heated cached data!
Solutions:
- Write a cache refresh page directly and operate it manually when online.
- The amount of data is not large, so it can be loaded automatically when the project starts.
The purpose is to load the data into the cache before the system goes online.
These are the caching avalanches, preheating, degrading and so on.